Chapter 7. Linux Virtual Server Overview
Red Hat Enterprise Linux LVS clustering uses a Linux machine called the active router to send requests from the Internet to a pool of servers. To accomplish this, LVS clusters consist of two basic machine classifications — the LVS routers (one active and one backup) and a pool of real servers which provide the critical services.
The active router serves two roles in the cluster:
To balance the load on the real servers.
To check the integrity of the services on each of the real servers.
The backup router's job is to monitor the active router and assume its role in the event of failure.
7.1. A Basic LVS Configuration
Figure 7-1 shows a simple LVS cluster consisting of two layers. On the first layer are two LVS routers — one active and one backup. Each of the LVS routers has two network interfaces, one interface on the Internet and one on the private network, enabling them to regulate traffic between the two networks. For this example the active router is using Network Address Translation or NAT to direct traffic from the Internet to a variable number of real servers on the second layer, which in turn provide the necessary services. Therefore, the real servers in this example are connected to a dedicated private network segment and pass all public traffic back and forth through the active LVS router. To the outside world, the server cluster appears as one entity.
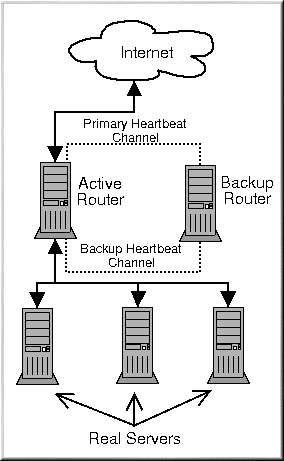
Service requests arriving at the LVS cluster are addressed to a virtual IP address or VIP. This is a publicly-routable address the administrator of the site associates with a fully-qualified domain name, such as www.example.com, and which is assigned to one or more virtual server[1]. Note that a VIP address migrates from one LVS router to the other during a failover, thus maintaining a presence at that IP address, also known as floating IP addresses.
VIP addresses may be aliased to the same device which connects the LVS router to the Internet. For instance, if eth0 is connected to the Internet, than multiple virtual servers can be aliased to eth0:1. Alternatively, each virtual server can be associated with a separate device per service. For example, HTTP traffic can be handled on eth0:1, and FTP traffic can be handled on eth0:2.
Only one LVS router is active at a time. The role of the active router is to redirect service requests from virtual IP addresses to the real servers. The redirection is based on one of eight supported load-balancing algorithms described further in Section 7.3 LVS Scheduling Overview.
The active router also dynamically monitors the overall health of the specific services on the real servers through simple send/expect scripts. To aid in detecting the health of services that require dynamic data, such as HTTPS or SSL, the administrator can also call external executables. If a service on a real server malfunctions, the active router stops sending jobs to that server until it returns to normal operation.
The backup router performs the role of a standby system. Periodically, the LVS routers exchange heartbeat messages through the primary external public interface and, in a failover situation, the private interface. Should the backup node fail to receive a heartbeat message within an expected interval, it initiates a failover and assumes the role of the active router. During failover, the backup router takes over the VIP addresses serviced by the failed router using a technique known as ARP spoofing — where the backup LVS router announces itself as the destination for IP packets addressed to the failed node. When the failed node returns to active service, the backup node assumes its hot-backup role again.
The simple, two-layered configuration used in Figure 7-1 is best for clusters serving data which does not change very frequently — such as static webpages — because the individual real servers do not automatically sync data between each node.
7.1.1. Data Replication and Data Sharing Between Real Servers
Since there is no built-in component in LVS clustering to share the same data between the real servers, the administrator has two basic options:
Synchronize the data across the real server pool
Add a third layer to the topology for shared data access
The first option is preferred for servers that do not allow large numbers of users to upload or change data on the real servers. If the cluster allows large numbers of users to modify data, such as an e-commerce website, adding a third layer is preferable.
7.1.1.1. Configuring Real Servers to Synchronize Data
There are many ways an administrator can choose to synchronize data across the pool of real servers. For instance, shell scripts can be employed so that if a Web engineer updates a page, the page is posted to all of the servers simultaneously. Also, the cluster administrator can use programs such as rsync to replicate changed data across all nodes at a set interval.
However, this type of data synchronization does not optimally function if the cluster is overloaded with users constantly uploading files or issuing database transactions. For a cluster with a high load, a three-tiered topology is the ideal solution.